

这比赛挺无语的,给一堆身份证,也是第一次了解到身份证的编码规则
身份证号码编码规则
国标GB 11643规定,全国所有公民的身份号码都是18位的特征码。所谓特征码,就是号码本身反映了公民的一些基本特征,比如籍贯、年龄、性别等。

- 第1、2位数字表示:所在省(直辖市、自治区)的代码;
| 华北 | 东北 | 华东 | 华中/华南 | 西南 | 西北 | 台湾 | 港澳 |
| 北京 11 | 辽宁 21 | 上海 31 | 河南 41 | 重庆 50 | 陕西 61 | 台湾 71 | 香港 81 |
| 天津 12 | 吉林 22 | 江苏 32 | 湖北 42 | 四川 51 | 甘肃 62 | 澳门 82 | |
| 河北 13 | 黑龙江 23 | 浙江 33 | 湖南 43 | 贵州 52 | 青海 63 | ||
| 山西 14 | 安徽 34 | 广东 44 | 云南 53 | 宁夏 64 | |||
| 内蒙古 15 | 福建 35 | 广西 45 | 西藏 54 | 新疆 65 | |||
| 江西 36 | 海南 46 | ||||||
| 山东 37 |
- 第3、4位数字表示:所在地级市(自治州)的代码;

- 第5、6位数字表示:所在区(县、自治县、县级市)的代码;

- 第7—14位数字表示:出生年、月、日;
- 第15、16位数字表示:所在地的派出所的代码;
- 第17位数字表示性别:奇数表示男性,偶数表示女性;
- 第18位数字是校检码:是根据《中华人民共和国国家标准GB 11643-1999》中有关公民身份号码的规定,根据精密的计算公式计算出来的。
顺序码
顺序码表示在同一地址码所标识的区域范围内,对同年、同月、同日出生的人编定的顺序号,顺序码的奇数分配给男性,偶数分配给女性。
国标GB/T 10114规定,县级以下行政区划指镇、乡、民族乡及街道;县级以下行政区划代码由三位数字构成,具体划分为:001~099表示街道;100~199表示镇、民族镇;200~399表示乡、民族乡、苏木(内蒙的基层行政单位)。
校验码
校验码采用ISO 7064:1983,MOD 11-2校验算法对前面的地址码、出生日期码和顺序码进行校验。
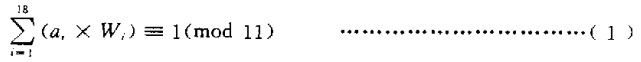

将上面公式稍作变换,具体是将a1×w1从求和表达式中提取出来
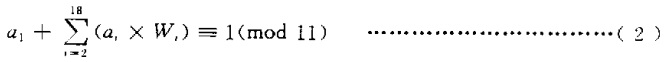
公式中a1就是我们要求的校验码字符值,其取值范围是0~10。当a1=10时,用罗马字符X表示
根据上面公式(2),只要求出第2~18位的∑ai×wi ,就能换算出校验码的值
第一步,列出该身份号码的本体码,结果如下

第二步,依据公式wi=(2^(i-1))(mod 11)计算加权因子

第三步,计算各位置上的乘积

第四步,乘积求和:∑ai×wi=7+9+0+5+0+32+4+0+6+21+7+18+20+5+40+36+2=212。
第五步,对11取模:∑ai×wi(mod 11)=212%11=3。
第六步,求出校验码字符值,根据(3+a1)≡1(mod 11),算出a1=9。
因此,该男性公民身份号码的本体码为110108201712215919
为了方便查找最终总结出了一个关系表,方便查阅

因为身份证有着校验码这个机制,所以我们是可以验证他给的身份证是否是合规的
我们把错误的校验码拼接起来
import re
# 判断身份证号码是否合法的函数
def is_id_card(id_card):
# 正则表达式,用于验证身份证号格式(18位身份证)
reg_id_card = re.compile(r'^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])(\d{3}(\d|X|x))$')
# 使用正则表达式进行初步验证
if reg_id_card.match(id_card):
# 如果是18位身份证,进行校验码计算
if len(id_card) == 18:
# 加权因子,用于计算校验码
id_card_wi = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
# 校验码对应的值
id_card_y = [1, 0, 10, 9, 8, 7, 6, 5, 4, 3, 2]
# 用于存储加权和
id_card_wi_sum = 0
# 计算加权和
for i in range(17):
id_card_wi_sum += int(id_card[i]) * id_card_wi[i]
# 计算出校验码的模数
id_card_mod = id_card_wi_sum % 11
# 获取身份证的最后一位(校验位)
id_card_last = id_card[17]
# 如果模数是2,校验位可以是"X"或"x"
if id_card_mod == 2:
if id_card_last.upper() == "X":
return True # 校验成功
else:
return False # 校验位错误
else:
# 否则,校验位应与id_card_y数组中对应的值相等
if id_card_last == str(id_card_y[id_card_mod]):
return True # 校验成功
else:
return False # 校验位错误
else:
# 正则表达式验证不通过
return False
# 读取文件中的身份证号码列表
try:
with open('./sfz.txt', 'r', encoding='utf-8') as file:
id_card_numbers = file.readlines()
# 去除每一行的多余空格,并验证身份证号是否合法
invalid_ids = [] # 存储不合法身份证号的最后一位
for id_card_number in id_card_numbers:
id_card_number = id_card_number.strip() # 去掉首尾空白字符
if id_card_number:
# 调用 is_id_card 函数进行验证
if not is_id_card(id_card_number): # 如果身份证号不合法
invalid_ids.append(id_card_number[-1]) # 保存不合法身份证号的最后一位
# 输出不合法身份证号的最后一位,不带空格
print("".join(invalid_ids)) # 输出为一行,不带空格
except FileNotFoundError:
print("文件未找到,请检查文件路径是否正确。")
except Exception as e:
print("出现错误:", e)
//(脚本搞了半天没搞出来了,这里借用了Peterpan师傅的脚本)得到 746869735f69735f7077645f6a37316e617332
然后再进行 hex 解码,得到key: this_is_pwd_j71nas2
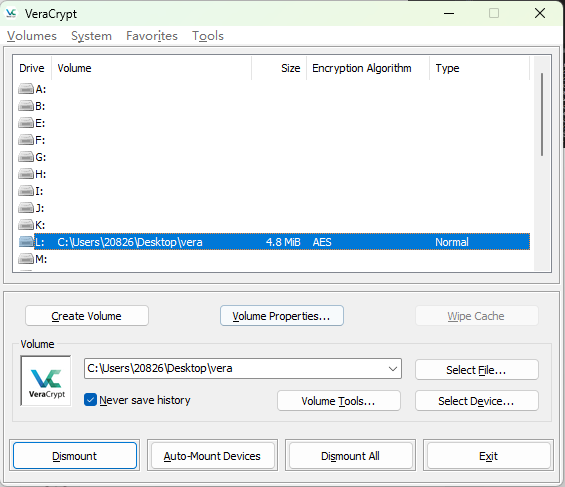
文件名是vera,所以很明显使用veracrypt挂载
成功挂载
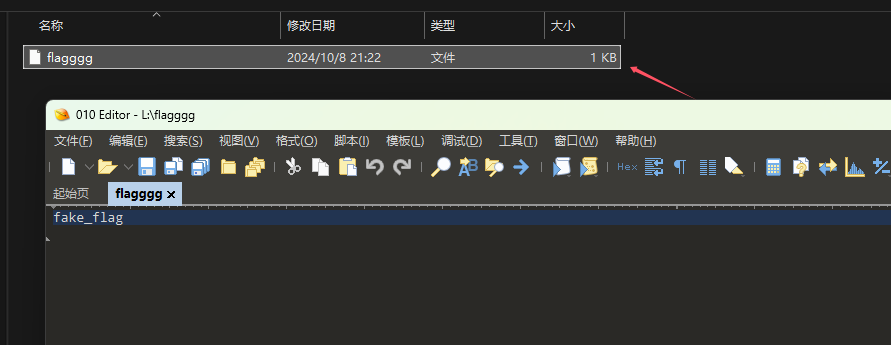
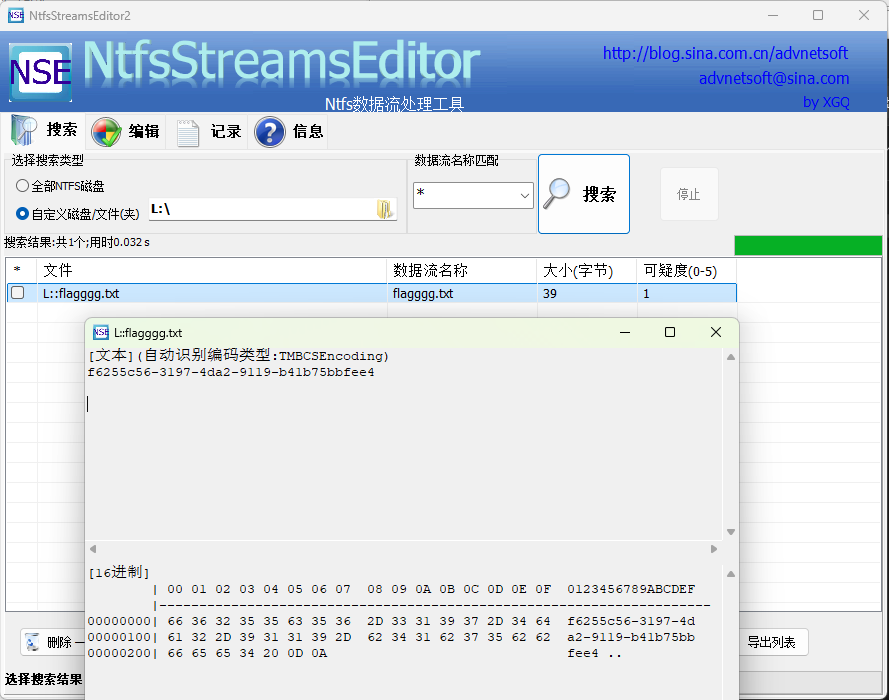
文本中没有隐写内容,但是这个文件足足有1kb大小,所以可以尝试考虑NTFS
使用NtfsStreamsEditor2扫描,果然里面藏有文件
Comments | NOTHING